Introduction
Like any good web developer, I have a tendency to poke around at people’s web sites to see if I can figure out how they’re implemented. After poking at enough sites, I started noticing that people were putting some weird and interesting stuff in their HTTP headers. So, a couple of weeks ago, I decided to actually go out and see what I could find by scrounging around in HTTP headers in the wild. A header safari, if you will. These are the results of my hunt.
Headers?
HTTP is the protocol used to transmit data on what we know as “the web”. At the beginning of every server response on the web, there’s a bit of text like:
The top line specifies the protocol version of HTTP and a response code (200 in this case) used to indicate the outcome of a request. Following that are a bunch of lines that should consist of a field name (like “Connection”), followed by a colon, and then followed by a value (like “close” or “keep-alive”). These lines of text are the HTTP response headers. Immediately after the headers is a blank line, followed by the content of the message, such as the text of a web page or the data of an image file.
Technical Mumbo Jumbo
Want to examine the headers of a site for yourself? Try curl:
In the output of the above the first few lines are the headers, then there are a couple of line breaks, and then the body. If you just want to see the headers, and not the body, use the -I option instead of -i. Be forewarned, however, that some servers return different headers in this case, as curl will be requesting the data using a HEAD request rather than a GET request.
What I did to gather all of these headers was very similar. First, I downloaded an RDF dump of the Open Directory Project’s directory, and pulled out every URL from that file. Then, I stuck all of the domain names of these URL’s in a big database. A simple multithreaded Python script was used to download all of the index pages of these URL’s using PycURL and stick the headers and page contents in a database. When that was done, I had a database with 2,686,155 page responses and 23,699,737 response headers. The actual downloading of all of this took about a week.
This is, of course, not anywhere near a comprehensive survey of the web. Netcraft received responses from 70,392,567 sites in its August 2005 web survey, so I hit around 3.8% of them. Not bad, but I’m sure there’s a lot of interesting stuff I’m missing.
Obligatory Mention of Long Tail
First of all, yes, HTTP headers form something like a long tail:
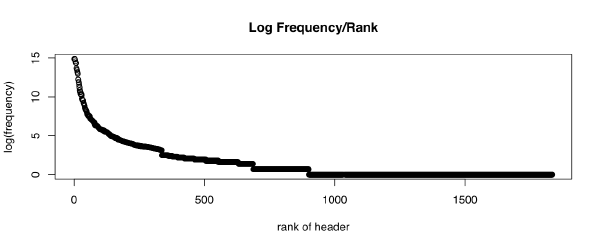
In particular, hapax legomena (one-offs) make up over half of the headers found. I expected this. Unfortunately for me, however, a lot of the really interesting stuff is over on that long flat section of the long tail. Which means I spent a lot of time poring over one-offs looking for interesting stuff. Weee.
It’s a good thing I’m easily amused.
Off with Her Headers
I found 891 instances of:
Which brought back memories of the days when Netscape was reviled by developers the world ’round, and had not yet achieved its ultimate (albeit posthumous) glory with Firefox. It’s nice to know comments by frustrated engineers have such a long half-life on the Internet. There are a few variants on this header:
Similarly, people are still blocking Microsoft’s Dumb Tags:
Speaking of Microsoft, apparently the IIS team felt the need to advertise the domain of the site the user was accessing in every page request:
How completely and utterly unnecessary…
They’re not the only ones, though. WebObjects powered sites spit out:
Go team!
This cute header is courtesy of Caudium, a webserver written partially in Pike:
The webmaster of www.kfki.hu should be commended for being on the bleeding edge, both using Caudium and including lots of Dublin Core metadata in the headers. Although, 32 headers seems a bit much, which is why I’m not going to show them all:
Contrary to popular belief, there are people out there using Smalltalk on the web. Two of them. One Smalltalk software company running a web server written in Smalltalk, and another:
running a Smalltalk user’s group web site with a wiki written on Smalltalk on a web server written in, you guessed it: Smalltalk. Cool.
And, of course, it wouldn’t be the Internet without an appearance by a BOFH:
The actual URL it points to has been obscured to protect the guilty, and a local mirror provided in its stead.
Missed Cneonctions
This header:
and its variant:
were two of the headers which first spurred my interest in HTTP headers.
imdb.com, amazon.com, gamespy.com, and google.com have all at various times used these or similar misspellings of connection, and I’m not by any means the first to have noticed. My first thought was that this was just a typo. After more consideration, however, I now believe this is something done by a hackish hardware load balancer trying to “remove” the connection close header when proxying for an internal server. That way, the connection can be held open and images can be transmitted through the same TCP connection, while the backend web server doesn’t need to be modified at all. It just closes the connection and moves on to the next request. Ex-coworker and Mudd alumus jra has a similar analysis.
Another data point which would back this up is the Oracle9iAS Web Cache rewriting:
as
Headers with “X-Cnection: close” appear to be the result of a similar trick.
One ISP/web host is kind enough to include their web address and phone number in every request to any of their hosted servers:
This is just super-awesome. I once spent a good hour trying to find a technical contact for a certain monstrous job site to tell them their servers had been compromised and were displaying the following message to visitors:
You are being sniffed by Carnivore.
Your nation is secure.
…………..OCR IS WATCHING YOU…………..
Content-type: text/html
The message, funnily enough, was being relayed by modifying the HTTP headers.
C is for Cookie
Cookies 2 were defined in RFC 2965, way back in October of 2000. As far as I know, Opera is the only browser in widespread use to support them. It’s sad, really, as the original cookie spec that Netscape came up with is kind of lame. Specifically, Netscape’s spec defines the expiration as a date, which is vulnerable to clock skew on the user’s system making the cookie expire early. The Cookies-2 spec, on the other hand, uses a max-age attribute, specifying the lifetime of the cookie in seconds:
There are also Comment and CommentURL fields which explain what the cookie is for, but I have yet to find a header which uses them. *sigh* On the other hand, I did find 518 Set-Cookie2 headers, which, while miniscule compared to the 764,976 SetCookie headers I received, is more than I expected. It looks like software written by Sun is responsible for most of these.
A bunch of servers spit out:
Doh! Time to cycle some log files.
Pingback discovery headers like this show up a lot (2370 times):
I don’t even know what to say to this, found at ebrain.ecnext.com:
At least they’re not alone, as www.charlottesweb.hungerford.org will keep them company:
And www.station.lu:
The list goes on…
The Coral Content Distribution Network has been getting some buzz lately, so I was interested to see some
headers show up. This header is used to tell Coral that if Coral can’t handle the load of requests for cached copies of your page, it should redirect these requests back to your site.
Why anyone would think to themselves, “Gee, if a massively scalable caching service running on hundreds of geographically distributed computers can’t handle the load of people wanting to look at my site, I’ll just have them bounce people back at me”, I don’t know. Masochism perhaps?
Speaking of P2P technologies, I was interested to run across a KaZaA server:
It looked like it was running on someone’s DVR. Anyone have any pointers as to what software does that?
Along the same lines, haha:
They’re not even the only ones using “X-Disclaimer”, a bunch of other sites do too:
It looks like Tux Games is trying to extend the venerable RFC 1097 to the web:
Personally, I would’ve gone for: “X-Superliminal: Hey you, buy some games!”.
I’m sure these kind folks would be first adopters:
This person wants to make their opinion known, so here it is:
To which I say: Take off every ‘zig’!! You know what you doing.
Robot Rock
I’d never really paid much attention to the Robots header:
as it’s mostly used to disable indexing of a page and is intended to be used in a meta tag in the HTML itself, not in the HTTP headers.
However, it seems Google has added a new NOARCHIVE attribute, so let’s see who’s using it in their headers rather than in the meta tags like Google specifies.
It looks like the Singapore-based “Ministry of Pets” doesn’t want to be cached, as does the Civil Engineering department at São Paulo Polytechnic University, the realtime-3d software company MultiGen Paradigm, Swiss handicraft company Schweizer Heimatwerk, a Swiss kitesailing site, the Ragin’ Cajun Cafe in Hermosa Beach, CA, the London-based BouncingFish web consultancy, and the French financial paper La Tribune. That’s it.
BouncingFish even goes so far as to use an additional GOOGLEBOT header:
How many of these sites are not being cached by Google? Zero. Which just goes to show that one shouldn’t just expect mix-and-matching of specs to work.
Along the same vein, I don’t think the first two headers below will work as expected:
Except, possibly, in spiders using Perl’s HTML::HeadParser module. And, of course, we’ve already seen that the third header probably won’t work, either.
While I’m on the subject of Google… all Blogspot sites spit out:
So Blogger folks, whatcha doin’?
It’s Funny, Laugh
The fine folks at www.basement.com.au want to make it clear that:
Some people have a lot of fun with headers, as seen here:
This is the only ascii art I found:
and it had me puzzled, until I realized it’s a telnet server, and the above is a really clever hack to redirect browsers towards HTML-land.
This made me laugh:
Apparently the site has an alter-ego, as well.
www.wrestlingdb.com has some interesting headers. A few requests gets:
which is about as entertaining as watching a real wrestling match.
Totally Ellet
Just so everyone knows, Frostburg students are so totally leet, they don’t even need to spell it correctly:
Speaking of which, apparently some guy named morris would like his visitors to know that he 0wnzor$ them:
Not sure where that box you rooted and are browsing the web from is located? Never fear, mobileparty.net will tell you:
And, for those who were wondering, the Texarkana Police are the world’s finest, at least in the HTTP headers department:
These nederlanders are representin’ for the westside:
Western Europe, that is. Jaaa.
Speaking of furriners, anyone care to translate:
Similarly:
Going back to my discussion on standards, localizing headers that are used to actually do stuff is a bad idea:
ObRef
The Democrats called, they want you to know they found their sense of humor:
Make sure to hit it a few times for optimum goodness:
In the politics vein:
Yes! Someone just made my day. I love Al Bundy quotes:
I was disappointed in the lack of mention of mules, donkeys, or garden gnomes, but at least llamas, mice, and loons are well represented:
From: www.teevee.org
From: www.kingssing.de
From: www.eod.com
Speaking of strange characters, apparently the Wicked Witch of the West and Spongebob Squarepants cohabitate at www.harbor-club.com:
Who knew?!
As if we needed further proof that the soft underbelly of the Internet is full of cults, slowly corrupting the moral fabric of society, I present:
From the looks of things, Living Slack Master Bob Dobbs is giving Jesus a run for his money among Oregonian carpenters and their web designers. They join such luminaries as R. Crumb, Devo, and Bruce Cambell.
And if you thought that was an obscure meme, try this on for size:
When I first saw an X-Han header, I thought for sure the contents would be “Shot first!”, but instead I found something more obscure:
While we’re on pop culture allusions:
And it would be difficult to be more obscure than this:
Finally, old school Mac-diehards should appreciate:
Connection: close
Back when I was interviewing for an internship at Tellme Networks, they had a comment buried on their homepage that said:
I thought this was just way awesome. However, if I was disappointed when they removed that comment, I’m even more disappointed to report that I have yet to find a single HTTP header offering me a cool job. What’s wrong with you people?! I’m supposed to be able to find anything on the Internet!
I was, at least, thanked for my efforts, and I found the answer to life, the universe, and everything!
You’re welcome! And thank you all, for making the Internet so interesting!